CLIP Interrogator: Frequently Asked Questions
What is CLIP Interrogator?
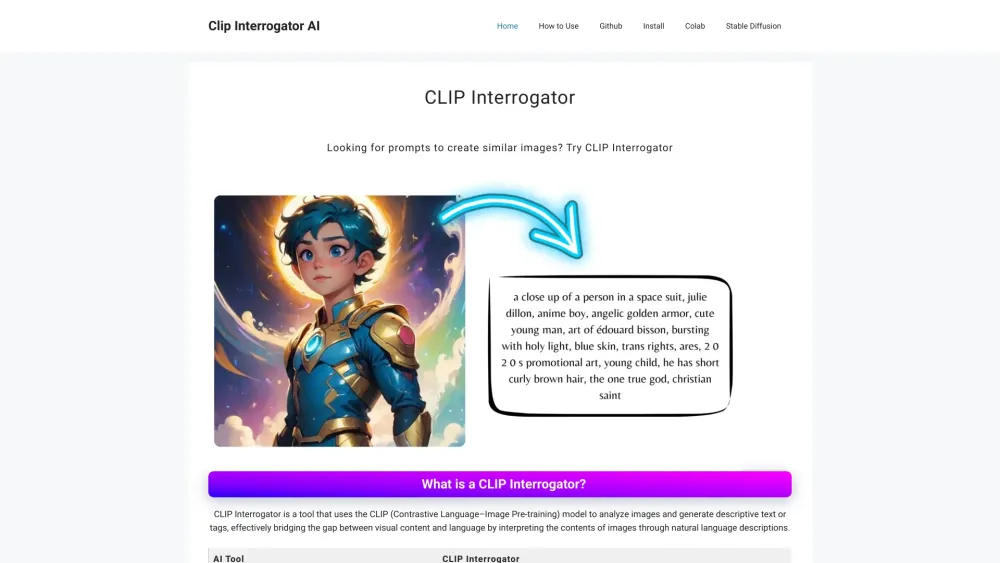
An intelligent image analysis system that interprets pixel data through multimodal AI—converting photographs, illustrations, or screenshots into precise, evocative, and actionable text.
How do I use CLIP Interrogator?
Upload any image, and the tool automatically applies BLIP for semantic grounding and CLIP-based retrieval to surface optimal descriptive tags, stylistic modifiers, and compositional cues—ideal for diffusion model prompting.
What makes CLIP Interrogator different from basic image captioning tools?
Unlike single-model captioners, it combines generative and contrastive intelligence—prioritizing relevance, diversity, and prompt utility over literal description alone.
Where can I try CLIP Interrogator?
It’s freely available as a hosted Gradio app on Hugging Face—no installation required. Just visit the official link to begin analyzing images in seconds.
Which models does it support under the hood?
Default configuration uses BLIP-2 for robust initial captioning, paired with multiple CLIP variants (ViT-L/14, OpenCLIP-HiT) for high-fidelity text-image alignment and phrase ranking.
Is my data private when using CLIP Interrogator?
Yes—images are processed client-side or in ephemeral server sessions and never stored, shared, or used for training. The tool prioritizes user privacy and responsible AI practices.